A Combined Comparative and Phylogenetic Analysis of the Chapacuran Language Family
Authors:
Citation:
Details:
Published: 7 July, 2016.
Download:
Abstract:
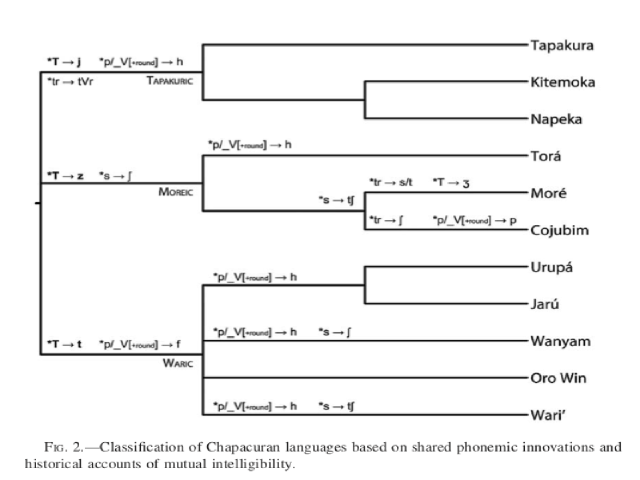
The Chapacuran language family, with three extant members and nine historically attested lects, has yet to be classified following modern standards in historical linguistics. This paper presents an internal classification of these languages by combining both the traditional comparative method (CM) and Bayesian phylogenetic inference (BPI). We identify multiple systematic sound correspondences and 285 cognate sets of basic vocabulary using the available documentation. These allow us to reconstruct a large portion of the Proto-Chapacuran phonemic inventory and identify tentative major subgroupings. The cognate sets form the input for the BPI analysis, which uses a stochastic Continuous-Time Markov Chain to model the change of these cognate sets over time. We test various models of lexical substitution and evolutionary clocks, and use ethnohistorical information and data collection dates to calibrate the resulting trees. The CM and BPI analyses produce largely congruent results, suggesting a division of the family into three different clades.