Bayesian Phylolinguistics
Authors:
Citation:
Details:
Published: 9 September, 2020.
Download:
Abstract:
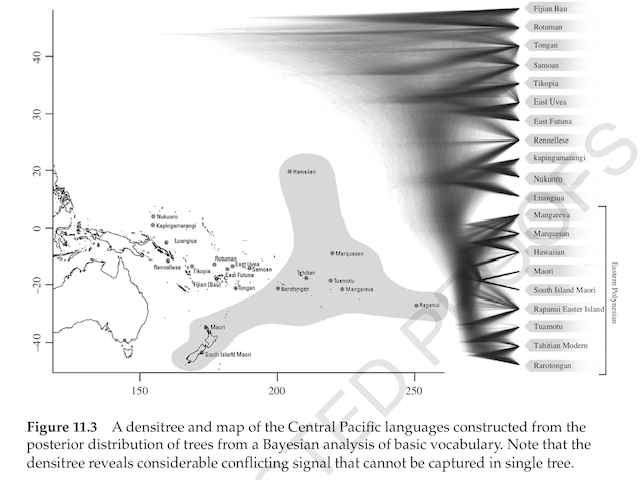
Change is coming to historical linguistics. Big, or at least “big‐ish” data (Gray and Watts 2017), are now becoming increasingly available in the form of large web‐ accessible lexical, typological, and phonological databases (e.g., Greenhill et al. 2008, Bowern 2016, Moran et al. 2014, Dryer and Haspelmath 2013, Bickel et al. 2017) and the soon to be released Lexibank, Grambank, Parabank, and Numeralbank (http:// www.shh.mpg.de/180672/glottobank). This deluge of data is way beyond the ability of any one person to process accurately in their head. The deluge will thus inevitably drive the demand for appropriate computational tools to process and analyze the vast wealth of freely available linguistic information. Historical linguistics has long dabbled in computational and quantitative approaches (e.g., Chrétien 1943). The search for a rigorous methodology to make accurate inferences about subgrouping and timing of language splits first led to a quantitative subgrouping approach called lexicostatistics and extended those to dating with an approach called glottochronology. However, severe shortcomings were quickly identified with both lexicostatistics and glottochronology and led to an almost puritanical rejection of these approaches. More recently, new Bayesian phylogenetic methods from evolutionary biology – which do not share the fatal shortcomings of lexicostatistics and glottochronology – have been applied to linguistic questions. In this chapter we review the history of quantitative approaches to language subgrouping and dating, and then turn specifically to Bayesian phylogenetic methods and their utility for historical linguistics.
Related links / Media:
Nothing found.