Blowing in the wind: Using ‘North Wind and the Sun’ texts to sample phoneme inventories.
Authors:
Citation:
Details:
Published: 6 June, 2021.
Download:
Abstract:
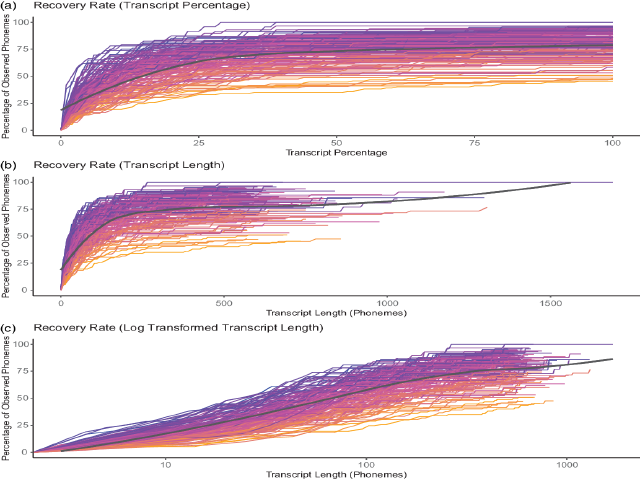
Language documentation faces a persistent and pervasive problem: How much material is enough to represent a language fully? How much text would we need to sample the full phoneme inventory of a language? In the phonetic/phonemic domain, what proportion of the phoneme inventory can we expect to sample in a text of a given length? Answering these questions in a quantifiable way is tricky, but asking them is necessary. The cumulative collection of Illustrative Texts published in the Illustration series in this journal over more than four decades (mostly renditions of the ‘North Wind and the Sun’) gives us an ideal dataset for pursuing these questions. Here we investigate a tractable subset of the above questions, namely: What proportion of a language’s phoneme inventory do these texts enable us to recover, in the minimal sense of having at least one allophone of each phoneme? We find that, even with this low bar, only three languages (Modern Greek, Shipibo and the Treger dialect of Breton) attest all phonemes in these texts. Unsurprisingly, these languages sit at the low end of phoneme inventory sizes (respectively 23, 24 and 36 phonemes). We then estimate the rate at which phonemes are sampled in the Illustrative Texts and extrapolate to see how much text it might take to display a language’s full inventory. Finally, we discuss the implications of these findings for linguistics in its quest to represent the world’s phonetic diversity, and for JIPA in its design requirements for Illustrations and in particular whether supplementary panphonic texts should be included.
Related links / Media:
Nothing found.