Lexibank, a public repository of standardized wordlists with computed phonological and lexical features
Authors:
Citation:
Details:
Published: 6 June, 2022.
Download:
Abstract:
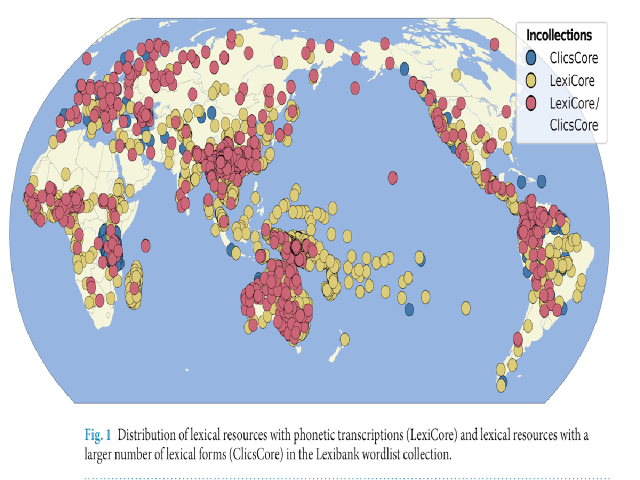
the past decades have seen substantial growth in digital data on the world’s languages. at the same time, the demand for cross-linguistic datasets has been increasing, as witnessed by numerous studies devoted to diverse questions on human prehistory, cultural evolution, and human cognition. Unfortunately, most published datasets lack standardization which makes their comparison difficult. Here, we present a new approach to increase the comparability of cross-linguistic lexical data. We have designed workflows for the computer-assisted lifting of datasets to Cross-Linguistic Data Formats, a collection of standards that make these datasets more Findable, accessible, Interoperable, and Reusable (FAIR). We test the Lexibank workflow on 100 lexical datasets from which we derive an aggregated database of wordlists in unified phonetic transcriptions covering more than 2000 language varieties. We illustrate the benefits of our approach by showing how phonological and lexical features can be automatically inferred, complementing and expanding existing cross-linguistic datasets.