Lexibank 2: pre-computed features for large-scale lexical data.
Authors:
Citation:
Details:
Published: 6 June, 2025.
Download:
Abstract:
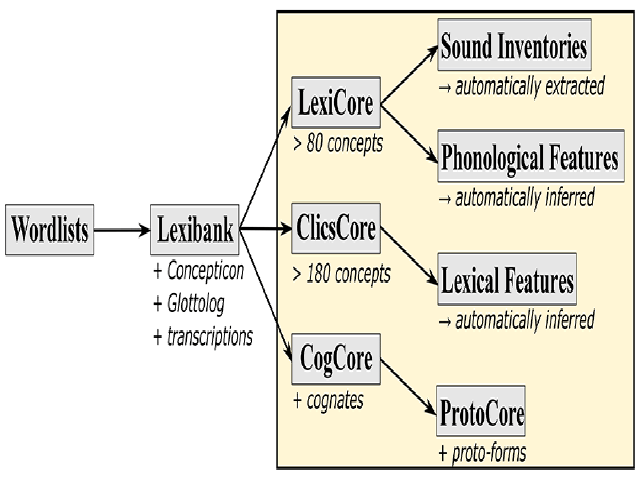
Large-scale lexical and grammatical datasets nowadays play an important role in comparative linguistics. However, the lack of standardization remains a challenge exacerbating extension and reuse of published data. We present an updated version of Lexibank, a large-scale lexical dataset, expanding on previous efforts to standardize and unify cross-linguistic data. This new version includes over 3,100 languages and more than one-and-a-half million word forms, substantially broadening the scope and utility of the previous resource. Our dataset has been systematically curated using a dedicated computer-assisted workflow designed specifically for the lifting of published wordlist data to the standards recommended by the Cross-Linguistic Data Formats initiative. The expanded dataset features standardized references to language varieties, standardized semantic glosses that reference the concepts expressed by individual word forms, and standardized phonetic transcriptions for all word forms that our repository contains. Based on those standardizations we pre-compute semantic and phonological features, which can be used to carry out extensive automated analyses. We illustrate this potential by providing dedicated database queries to (1) infer words that are similar in pronunciation and meaning, (2) identify concepts that are colexified across languages in our sample, and (3) assess the semantic diversity of etymologically related words. These queries are not only fast to execute but also global in their scope, due to the largescale coverage provided by Lexibank 2. The queries are also easy to extend, thus having the potential to contribute to various studies in historical linguistics, linguistic typology, and related disciplines. The updated dataset is a substantial step forward in the effort to create comprehensive, standardized, and accessible linguistic resources.
Related links / Media:
Nothing found.