Variation in phoneme inventories: quantifying the problem and improving comparability
Authors:
Citation:
Details:
Published: 11 November, 2023.
Download:
Abstract:
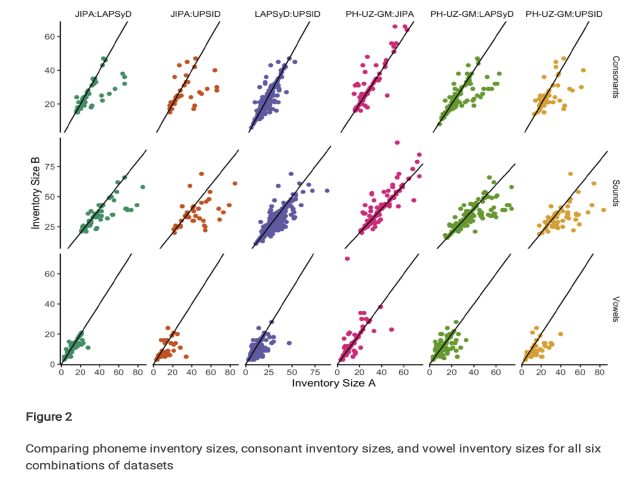
For over a century, the phoneme has played a central role in linguistic research. In recent years, collections of phoneme inventories, originally designed for cross-linguistic purposes, have increasingly been used in comparative studies involving neighbouring disciplines. Despite the extended application of this type of data, there has been no research into its comparability or tests of its reliability. In this study, we carry out a systematic comparison of nine popular phoneme inventory collections. We render them comparable by linking them to standardised formats for the handling of cross-linguistic datasets, develop new measures to test both size and similarity, and release the organised data in supplementary material. We find considerable differences in inventories supposedly representing the same language variety, both in terms of size and transcriptional choices. While some of these differences appear to be predictable, reflecting design decisions in the different collections, much of the observed variation is unsystematic. These results should sound a note of caution for comparative studies based on phoneme inventories, which we suggest need to take the question of comparability more seriously. We make a number of proposals for improving the comparability of phoneme inventories.
Related links / Media:
Nothing found.