Modelling admixture across language levels to evaluate deep history claims
Authors:
Citation:
Details:
Published: 3 March, 2023.
Download:
Abstract:
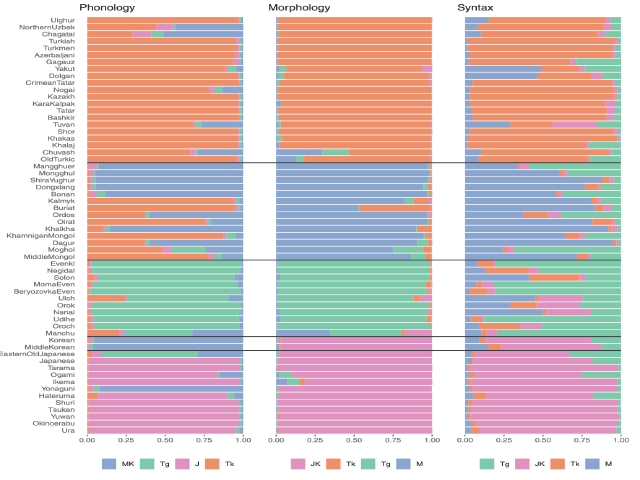
The so-called ‘Altaic’ languages have been subject of debate for over 200 years. An array of different data sets have been used to investigate the genealogical relationships between them, but the controversy persists. The new data with a high potential for such cases in historical linguistics are structural features, which are sometimes declared to be prone to borrowing and discarded from the very beginning and at other times considered to have an especially precise historical signal reaching further back in time than other types of linguistic data. We investigate the performance of typological features across different domains of language by using an admixture model from genetics. As implemented in the software STRUCTURE, this model allows us to account for both a genealogical and an areal signal in the data. Our analysis shows that morphological features have the strongest genealogical signal and syntactic features diffuse most easily. When using only morphological structural data, the model is able to correctly identify three language families: Turkic, Mongolic, and Tungusic, whereas Japonic and Koreanic languages are assigned the same ancestry.
Related links / Media:
Nothing found.