The Potential of Automatic Word Comparison for Historical Linguistics
Authors:
Citation:
Details:
Published: 1 January, 2017.
Download:
Abstract:
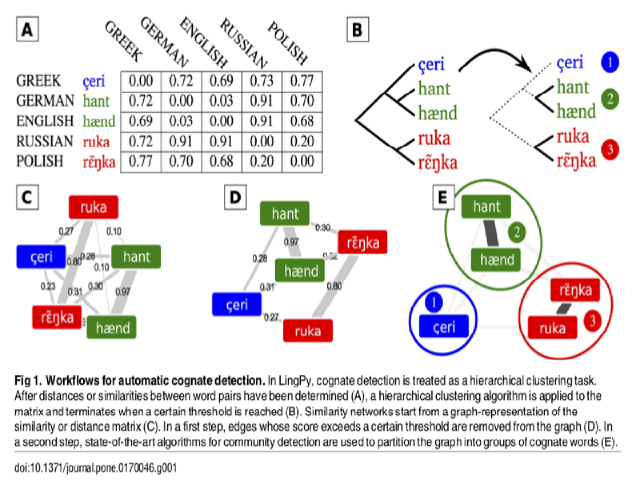
The amount of data from languages spoken all over the world is rapidly increasing. Traditional manual methods in historical linguistics need to face the challenges brought by this influx of data. Automatic approaches to word comparison could provide invaluable help to pre-analyze data which can be later enhanced by experts. In this way, computational approaches can take care of the repetitive and schematic tasks leaving experts to concentrate on answering interesting questions. Here we test the potential of automatic methods to detect etymologically related words (cognates) in cross-linguistic data. Using a newly compiled database of expert cognate judgments across five different language families, we compare how well different automatic approaches distinguish related from unrelated words. Our results show that automatic methods can identify cognates with a very high degree of accuracy, reaching 89% for the best-performing method Infomap. We identify the specific strengths and weaknesses of these different methods and point to major challenges for future approaches. Current automatic approaches for cognate detection—although not perfect—could become an important component of future research in historical linguistics.
Related links / Media:
Nothing found.