Project: grambank: a database of structural (typological) features of language

Grambank is a database of structural (typological) features of language. It consists of 195 logically independent features (most of them binary) spanning all subdomains of morphosyntax. The Grambank feature questionnaire has been filled in, based on reference grammars, for 2,467 languages. The aim is to eventually reach as many as 3,500 languages. The database can be used to investigate deep language prehistory, the geographical-distribution of features, language universals and the functional interaction of structural features.
Publications from this Project:
Enduring constraints on grammar revealed by Bayesian spatiophylogenetic analyses..
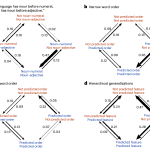
Verkerk A, Shcherbakova O, Haynie HJ, Skirgård H, Rzymski C, Atkinson QD, Greenhill SJ & Gray RD. 2025. Enduring constraints on grammar revealed by Bayesian spatiophylogenetic analyses. Nature Human Behaviour.
Human languages show astonishing variety, yet their diversity is constrained by recurring patterns. Linguists have long argued over the extent and causes of these grammatical ‘universals’. Using Grambank—a comprehensive database of grammatical features across the world’s languages—we tested 191 proposed universals with Bayesian analyses that account for both genealogical descent and geographical proximity. We find statistical support for about a third of the proposed linguistic universals. The majority of these concern word order and hierarchical universals: two types that have featured …
Abstract PDF 10.1038/s41562-025-02325-zDifferent models, different assumptions, different findings..

Shcherbakova O, Gast V, Greenhill SJ, Blasi DE, Gray RD, & Skirgård H. 2025. Different models, different assumptions, different findings: commentary on 'Replication and methodological robustness in quantitative typology' by Becker and Guzmán Naranjo. Linguistic Typology, 29, 587-590.
We are the authors of Shcherbakova et al. (2022). We welcome Becker and Guzmán Naranjo (2025) (henceforth B&GN)’s initiative to re-visit our findings. However, we find the framing of their paper misleading. While replication has been defined in many different ways (Clemens 2017: 333), the most common interpretation is that it involves reassessing a specific hypothesis with new data and the same methods (e.g. Minocher et al. 2021; National Academies of Sciences, Engineering, and Medicine 2019). Using the same data and different methods is commonly referred to as 'robustness analysis' (see …
Abstract PDF 10.1515/lingty-2025-0022The evolutionary dynamics of how languages signal who does what to whom.
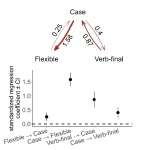
Shcherbakova O, Blasi DE, Gast V, Skirgård H, Gray RD, & Greenhill SJ. 2024. The evolutionary dynamics of how languages signal who does what to whom. Scientific Reports, 14, 7259.
Languages vary in how they signal “who does what to whom”. Three main strategies to indicate the participant roles of “who” and “whom” are case, verbal indexing, and rigid word order. Languages that disambiguate these roles with case tend to have either verb-final or flexible word order. Most previous studies that found these patterns used limited language samples and overlooked the causal mechanisms that could jointly explain the association between all three features. Here we analyze grammatical data from a Grambank sample of 1705 languages with phylogenetic causal graph methods. Our results …
Abstract PDF 10.1038/s41598-024-51542-5Societies of strangers do not speak grammatically simpler languages.
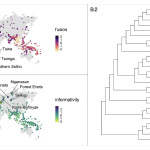
Shcherbakova O, Michaelis SM, Haynie HJ, Passmore S, Gast V, Gray RD, Greenhill SJ, Blasi DE, & Skirgård H. 2023. Societies of strangers do not speak grammatically simpler languages. Science Advances, 9 (33), eadf7704.
Many recent proposals claim that languages adapt to their environments. The linguistic niche hypothesis claims that languages with numerous native speakers and substantial proportions of nonnative speakers (societies of strangers) tend to lose grammatical distinctions. In contrast, languages in small, isolated communities should maintain or expand their grammatical markers. Here, we test these claims using a global dataset of grammatical structures, Grambank. We model the impact of the number of native speakers, the proportion of nonnative speakers, the number of linguistic neighbors, and the …
Abstract PDF 10.1126/sciadv.adf7704Grambank’s Typological Advances Support Computational Research on Diverse Languages.

Haynie H, Blasi DE, Skirgård H, Greenhill SJ, Atkinson QD, & Gray RD. Grambank’s Typological Advances Support Computational Research on Diverse Languages. In Beinborn L, Goswami K, Muradoğlu S, Sorokin A, Kumar R, Shcherbakov A, Ponti EM, Cotterell R & Vylomova E. Proceedings of the 5th Workshop on Research in Computational Linguistic Typology and Multilingual NLP (SIGTYP). Association for Computational Linguistics: Dubrovnik, Croatia.
Of approximately 7,000 languages around the world, only a handful have abundant computational resources. Extending the reach of language technologies to diverse, less-resourced languages is important for tackling the challenges of digital equity and inclusion. Here we introduce the Grambank typological database as a resource to support such efforts. To date, work that uses typological data to extend computational research to less-resourced languages has relied on cross-linguistic morphosyntax datasets that are sparsely populated, use categorical coding that can be difficult to interpret, and …
Abstract PDF OverviewGrambank reveals the importance of genealogical constraints on linguistic diversity and highlights the impact of language loss.

Skirgård H ....Greenhill SJ, Atkinson QD, & Gray RD. 2023. Grambank reveals the importance of genealogical constraints on linguistic diversity and highlights the impact of language loss. Science Advances, 9, eadg6175.
While global patterns of human genetic diversity are increasingly well characterized, the diversity of human languages remains less systematically described. Here, we outline the Grambank database. With over 400,000 data points and 2400 languages, Grambank is the largest comparative grammatical database available. The comprehensiveness of Grambank allows us to quantify the relative effects of genealogical inheritance and geographic proximity on the structural diversity of the world’s languages, evaluate constraints on linguistic diversity, and identify the world’s most unusual languages. An …
Abstract PDF 10.1126/sciadv.adg6175 OverviewA quantitative global test of the complexity trade-off hypothesis: the case of nominal and verbal grammatical marking.

Shcherbakova O, Gast V, Blasi DE, Skirgård H, Gray RD, & Greenhill SJ. 2022. A quantitative global test of the complexity trade-off hypothesis: the case of nominal and verbal grammatical marking. Linguistics Vanguard.
Nouns and verbs are known to differ in the types of grammatical information they encode. What is less well known is the relationship between verbal and nominal coding within and across languages. The equi-complexity hypothesis holds that all languages are equally complex overall, which entails trade-offs between coding in different domains. From a diachronic point of view, this hypothesis implies that the loss and gain of coding in different domains can be expected to balance each other out. In this study, we test to what extent such inverse coevolution can be observed in a sample of 244 …
Abstract PDF 10.1515/lingvan-2021-0011Grammatical complexity is only weakly influenced by the sociolinguistic environment.

Shcherbakova O, Michaelis SM, Haynie HJ, Greenhill SJ, Blasi DE, Gray RD, Gast V, & Skirgård H. 2022. Grammatical complexity is only weakly influenced by the sociolinguistic environment. Pp. 669-671, In Ravignani A, Asano R, Valente D, Ferretti F, Hartmann S, Hayashi M, Jadoul Y, Martins M, Oseki Y, Rodrigues ED, Vasileva O, & Wacewicz S. (Eds). Proceedings of the Joint Conference on Language Evolution (JCoLE). Joint Conference on Language Evolution (JCoLE). Nijmegen: Joint Conference on Language Evolution (JCoLE).
Recent studies claim that the social environment influences the evolution of language structures. In particular, grammatical complexity has been proposed to be lower in communities with looser social networks, higher numbers of L1 speakers, and higher proportions of L2 speakers (among others, Kusters 2003, Trudgill 2011, Lupyan & Dale 2010, Sinnemäki & Di Garbo 2018). The explanation for these relationships relies on the assumption that larger communities are exposed to more contact than smaller ones. Specifically, due to substantial proportions of L2 speakers in large communities, the more …
Abstract PDF 10.17617/2.3398549