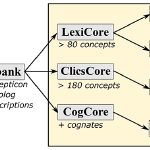
Project: Lexibank: a public repository of standardized wordlists with computed phonological and lexical features

The past decades have seen substantial growth in digital data on the world’s languages. At the same time, the demand for cross-linguistic datasets has been increasing, as witnessed by numerous studies devoted to diverse questions on human prehistory, cultural evolution, and human cognition. Unfortunately, most published datasets lack standardization which makes their comparison difficult. Here, we present a new approach to increase the comparability of cross-linguistic lexical data. We have designed workflows for the computer-assisted lifting of datasets to Cross-Linguistic Data Formats, a collection of standards that make these datasets more Findable, Accessible, Interoperable, and Reusable (FAIR). We test the Lexibank workflow on 100 lexical datasets from which we derive an aggregated database of wordlists in unified phonetic transcriptions covering more than 2000 language varieties. We illustrate the benefits of our approach by showing how phonological and lexical features can be automatically inferred, complementing and expanding existing cross-linguistic datasets.
Publications from this Project:
Lexibank 2: pre-computed features for large-scale lexical data..
Blum F, List JM, Barrientos C, Englisch J, Forkel R, Greenhill SJ & Rzymski C. 2025. Lexibank 2: pre-computed features for large-scale lexical data.. Open Research Europe, 5:126.
Large-scale lexical and grammatical datasets nowadays play an important role in comparative linguistics. However, the lack of standardization remains a challenge exacerbating extension and reuse of published data. We present an updated version of Lexibank, a large-scale lexical dataset, expanding on previous efforts to standardize and unify cross-linguistic data. This new version includes over 3,100 languages and more than one-and-a-half million word forms, substantially broadening the scope and utility of the previous resource. Our dataset has been systematically curated using a dedicated …
Abstract PDF 10.12688/openreseurope.20216.2Lexibank, a public repository of standardized wordlists with computed phonological and lexical features.
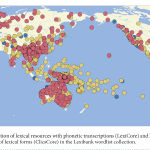
List JM, Forkel R, Greenhill SJ, Rzymski C, Englisch J & Gray RD. 2022. Lexibank, a public repository of standardized wordlists with computed phonological and lexical features. Scientific Data, 9(1): 316.
the past decades have seen substantial growth in digital data on the world’s languages. at the same time, the demand for cross-linguistic datasets has been increasing, as witnessed by numerous studies devoted to diverse questions on human prehistory, cultural evolution, and human cognition. Unfortunately, most published datasets lack standardization which makes their comparison difficult. Here, we present a new approach to increase the comparability of cross-linguistic lexical data. We have designed workflows for the computer-assisted lifting of datasets to Cross-Linguistic Data Formats, a …
Abstract PDF 10.1038/s41597-022-01432-0Managing Historical Linguistic Data for Computational Phylogenetics and Computer-Assisted Language Comparison.

Tresoldi T, Rzymski C, Forkel R, Greenhill SJ, List JM, & Gray R. 2022. Managing historical linguistic data for computational phylogenetics and computer-assisted language comparison. In Andrea L. Berez-Kroeker, Bradley McDonnell, Eve Koller, & Lauren B. Collister (Eds). Open Handbook of Linguistic Data Management.
Computational phylogenetics is a relatively recent branch of historical linguistics that uses quantitative techniques to investigate the history of related languages. As the classical comparative method is less explicit on the techniques for constructing phylogenies of language families (see discussion in Jacques & List 2019), such a new approach can complement traditional techniques for sub-grouping based on shared innovations (Ross & Durie 1996).
Abstract PDF 10.7551/mitpress/12200.001.0001The Database of Cross-Linguistic Colexifications, reproducible analysis of cross-linguistic polysemies.
Rzymski C, Tresoldi T, Greenhill SJ, Wu M-S, Schweikhard NE, Koptjevskaja-Tamm M, Gast V, et al. 2020. The Database of Cross-Linguistic Colexifications, Reproducible Analysis of Cross-Linguistic Polysemies. Scientific Data 7 (1): 1–12.
Advances in computer-assisted linguistic research have been greatly influential in reshaping linguistic research. With the increasing availability of interconnected datasets created and curated by researchers, more and more interwoven questions can now be investigated. Such advances, however, are bringing high requirements in terms of rigorousness for preparing and curating datasets. Here we present CLICS, a Database of Cross-Linguistic Colexifications (CLICS). CLICS tackles interconnected interdisciplinary research questions about the colexification of words across semantic categories in the …
Abstract PDF 10.1038/s41597-019-0341-x OverviewEmotion semantics show both cultural variation and universal structure.
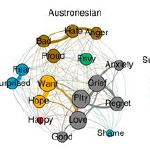
Jackson JC, Watts J, Henry TR, List JM, Forkel R, Mucha PJ, Greenhill SJ, Gray RD, & Lindquist KA. 2019 Emotion semantics show both cultural variation and universal structure. Science, 366, 1517-1522.
It is unclear whether emotion terms have the same meaning across cultures. Jackson et al. examined nearly 2500 languages to determine the degree of similarity in linguistic networks of 24 emotion terms across cultures (see the Perspective by Majid). There were low levels of similarity, and thus high variability, in the meaning of emotion terms across cultures. Similarity of emotion terms could be predicted on the basis of the geographic proximity of the languages they originate from, their hedonic valence, and the physiological arousal they evoke. Many human languages have words for emotions …
Abstract PDF 10.1126/science.aaw8160 Overview